Designing Data Intensive Applications

TOC
- Review
- Synopsis
- Chapter 1 Reliable, Scalable, and Maintainable Applications
- Chapter 2 Data Models and Query Languages
- Chapter 3 Storage and Retrieval
- Data structures that power your database
- hash indexes
- SSTables and LSM-Trees
- B-Trees
- comparing b-trees and LSM-trees
- Transaction Processing or Analytics?
- data warehousing
- Column-Oriented Storage
- Sort order in column storage
- Writing to column-oriented storage
- Aggregation: data cubes and materialized views
- Summary
- Chapter 4 Encoding and Evolution
- Part 2 Distributed Data
- Chapter 5 Replication
- Leaders and Followers
- Synchronous Versus asynchronous replication
- Setting up new followers
- Handling node outages
- Implementation of Replication Logs
- Problems with Replication Lag
- Reading Your Own Writes
- Monotonic Reads
- Consistent Prefix Reads
- Solutions for Replication Lag
- Multi-Leader Replication
- Use Cases for Multi-Leader Replication
- Handling Write Conflicts
- Leaderless Replication
- Detecting Concurrent Writes
- last write wins (discarding concurrent writes)
- Chapter 5 Summary
- Chapter 6 Partitioning
- Chapter 7 Transactions
- Slippery concept of a transaction
- Meaning of ACID
- Single-Object and Multi-Object Operations
- weak isolation levels
- Write Skew and phantoms
- serializability
- Chapter 7 Summary
- Chapter 8 Trouble with distributed systems
- Knowledge, Truth, and Lies
- System model and reality
- Chapter 8 Summary
- Chapter 9 Consistency and Consensus
- Part 3
- Chapter 10 Batch Processing
- Chapter 11 Stream Processing
- Chapter 12 The Future of Data systems
Review
The author teaches the user about modern data systems from b-trees and encoding to heterogenous data flow systems. Modern systems use several pieces of software to provide different queries experiences on data. These systems need to be kept in sync and up to date. He makes a persuasive point that distributed transactions as they exist today don't work well across different technologies. Stable message ordering and fault tolerant processing are stringent demands but much less expensive and robust than distributed transactions
Synopsis
Data Intensive if data is its primary challenge — the quantity, complexity or speed at which it is changing as opposed to compute-intensive
Who Should Read This Book
If your applications use the internet or have some kind of server/backend for storing or processing data. For software engineers, architects and technical managers who love t o code.
Outline
1. Fundamental ideas that underpin the design of data intensive applications
2. Move on from data stored on one machine to data that is distributed across multiple machines
3. Systems that derive some datasets from other datasets. Derived data often occurs in heterogenous systems: when there is no one database that can do everything well.
Chapter 1 Reliable, Scalable, and Maintainable Applications
Reliability tolerating hardware & software faults, human error Scalability measuring load & performance. Latency percentiles, throughput. _ Maintainability_ Operability simplicity & evolvability
Building blocks: - Store data (dbs) - Remember result (cache) - Allow users to search by keyword (search indexes) - Send message to another process (stream processing) - Periodically crunch a large amount of accumulated data (batch processing)
Reliability
Expectations: - The application performs the function that the user expected - It can tolerate the user making mistakes or using the software in unexpected ways - Its performance is good enough for the required use case, under the expected load and data volume - The system prevents any unauthorized access and abuse Continuing to work correctly, even when things go wrong
Fault is one component deviating from spec, whereas a failure is when the system as a whole stops providing required service to the user.
Hardware Faults
Hard disks have a mean time to failure of 10 to 50 years so if you have 10k disks one will fail a day. The old way was hardware redundancy. More machines and backup/start a new server but now users expect virtual machine instances that can become unavailable without warning. Software must handle these faults
Human errors
Configuration errors by humans were the leading cause of outages, hardware faults were only 10-25%
- Well-designed abstractions, discourage the wrong thing but don’t be too restrictive or they will work around
- Decouple where people make mistakes from places they can cause failures. E.g. sandboxes with real data
- Make it easy to recover via rollback and roll out gradually
- Setup clear monitoring
Scalability
How can we add computing resources to handle the additional load?
Describing Load
Define load parameters. Requests per second, ratio of reads to writes, number of users in a chat room, hit rate on cache. Could depend on average or bottlenecked by extreme cases
Describing performance
When increasing load and keep resources the same, how is the performance of the system? When you increase a load parameter, how much do you need to increase resources?
Response is how long it takes a client to see a response, latency is the duration that a request is waiting to be handled
Queueing delay often accounts for the increased time at high percentiles. When load testing continue to send without waiting for response
Approaches for Coping With Load
You will likely need to rethink your architecture on every order of magnitude of load increase
Scaling up & out. A system that scales automatically is called elastic.
Maintainability
Operability - make it easy for operations teams to keep the system running smoothly Simplicity - make it easy for new engineers to understand the system Evolvability - make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change.
Operability: making life easy for operations
Make rounding tasks easy, letting ops team focus on high value activities. - Good monitoring - Support for automation and integration with standard tools - Good documentation and operational model - Good default behavior and overriding defaults
Simplicity: Managing complexity
A good abstraction can hide a great deal of implementation detail
Evolvability: Making change easy
Requirements will likely be in constant flux Agile processes help, same with simplicity
Chapter 2 Data Models and Query Languages
Apps are built by layering one data model on top of another 1. App developer looks at real world (goods, actions, money, people) and model it in terms of objects or data structures and APIs 2. To store those you use a general-purpose JSON, XML, tables in a relational db or a graph model 3. Engineers who built your db decided on a way of representing that data in bytes of memory, on disk or on a network 4. Hardware engineers figured out how to represent bytes in terms of currents, pulses of light Cover #2 in this list in this chapter
Relational Model Versus Document Model
NoSQL adoption: - A need for greater scalability than relational db’s can achieve - Free and open source software - Specialized query operations - Frustration with the restrictiveness of relational schemas
The object-relational mismatch
Disconnect between tables, rows and columns and object oriented programming Consider a resume, first name, last name, user id but they have many jobs in their career. Ways to handle that - Traditional way, put positions, education in separate tables with a foreign key to users table - Structured data in a single row with querying inside those documents - Store it as a json and let the application interpret its structure and content. Cannot use db query
JSON model has better locality as if you search for jobs you will also get location vs multiple joins One to many/tree structure is predictive
Many to One and Many to Many
Storing id or text string is a matter of duplication. When you use an id, the part meaningful to humans is only stored in one place.
Id means it never has to change, you can update the translator. This is the idea behind normalization which requires many to one (many people live in one region or industry) Linked in model becomes many to many because they have multiple jobs pointing to multiple institutions
Query optimizers and ease of use made relational win out over network/hierarchical
Relational vs Document today
Document has schema flexibility, better performance due to locality and can be closer to the data structures used by the application. Relational has support for joins and many to one and many to many relationships
Documents have schema not enforced by db. Schema on read vs schema on write
Document db has doc locality but relational dbs like spanner, hbase and Cassandra use multi table index cluster and column family concepts to achieve the same
Relational supports JSON and doc supporting joins
Query Languages for Data
SQL is declarative Most programming languages are imperative
Imperative - tells the computer to perform certain operations in a certain order. Evaluating conditions, updating vars Declarative - specify the pattern of the data you want — what conditions and how the data should be transformed but not how. The query optimizer decides how
Declarative hides implementation details of db engine
Declarative lend themselves to parallel execution because imperative says do these in a particular order. The db is free to use a parallel implementation if there is any
Declarative queries on the web
HTML and css are declarative so you don’t have to apply all to each elt
MapReduce Querying
Mix of declarative and imperative. Snippet of code run how mapreduce thinks is best. Doc db uses mapreduce like syntax to do read-only queries across many docs
Graph-Like Data Models
Social graphs - vertices are people, edges indicate which know each other Web graph - vertices are web pages, and edges indicate HTML links to other pages Road or rail networks - vertices are junctions, and edges represent the roads or railway lines between them
Property Graphs
Each vertex consists of: - A unique id - Outgoing edges - Incoming edges - Collection of properties (key-value pairs) Each edge: - A unique id - Tail & head vertex - A label to describe the kind of relationship - Properties
Create Table vertices ( Vertex_id integer PRIMARY KEY, Properties Jason );
Edges ( Edge_id Tail vertex Head vertex Label Properties) Index on tail and head
1. Any vertex can have an edge connecting it with any other vertex.
2. Given a vertex, can traverse back and first via index
3. By using different labels for diff relationships can put several types of info in one graph
Cypher Query Language
Declarative language for property graphs. Let’s you look at the properties in vertices and edges
Can do the within *0 zero or more edges with sql but more awkward. 4 lines versus 29 lines
Triple-stores and SPARQL
Similar to property graph. Three part statements: (subject, predicate, objet) like (Jim, likes, bananas)
(I skipped this part as I’ve never encountered someone using these)
Summary
Big tree (hierarchical) -> relational model Added non-relational
Chapter 3 Storage and Retrieval
Big difference in engines optimized for transactional workloads and those that are optimized for analytics
Data structures that power your database
Db’s use a log internally, append only data file Need an index to prevent having to scan
hash indexes
Hash map key to byte offset Compaction of keys into newest value to save space Good for low number of keys with lots of writes
File format, deleting records (tombstone), crash recovery (store snapshot of map), concurrency control (one writer),
Bad at range queries
SSTables and LSM-Trees
Sorted String Table, sequence is sorted by key Binary search from your sparse index in memory
Add keys to a b-tree. When it reaches a size write to a new sstable file segment. Continue a new memtable instance
For reads look at mem table then on disk Periodically merge Keep a log on disk that isn’t sorted for crashes
Log-Structured Merge Tree (LSM)
LSM can be slow looking up a key that does not exist. They can use bloom-filters Different compaction modes
B-Trees
Most common. Breaks down into fixed-size blocks or pages. Read or write page at a time Keys point to ref blocks, copy on write B tree with n keys has depth Logan.
comparing b-trees and LSM-trees
LSM faster for writes, b-trees for reads. Reads are slower because of having to check more data structures and different stages of compaction Benchmarks are inconclusive and sensitive to workloads
Advantages of LSM-trees
B-tree must write everything at least twice. Once to write-ahead-log and once to the tree page. And it has to write an entire page at a time even for a few bytes
LSM might have one write cause in multiple writes due to compaction over the db lifetime. Called write amplification And can harm ssds
LSM write less because its smaller and its sequential
LSM can be compressed better and b-trees have fragmentation.
Downsides of LSM-trees
Compaction process can interfere with ongoing reads and writes
At high percentiles, b trees are more predictable
At high write throughput, splitting writing the mental be and compaction running in the background. If the compaction never runs you run out of space on the disk
Other indexing structures
Secondary index, value is a list or making each key unique by adding a row identifier
Heap file approach for secondary indexes is described but I doubt I’ll ever have to know this.
Multi-column indexes
Finding restaurants by lat and long, b and LSM can’t do this efficiently. R-trees are used. PostgreSQL’s generalized search tree
Full text and fuzzy indexes
Levenshtein automation which supports efficient search for worlds within a given edit distance. Lucerne uses something like a trie
keeping everything in memory
Snapshots Battery powered ram Restart from over the network or ram
MemSQL, VoltDB Faster not because of avoiding disk but because they don’t have overheads of encoding for a form that can be written to disk
Reid’s has database like interface to priority queues and sets which are hard to write to disk
Transaction Processing or Analytics?
In the early days, a write corresponded to a commercial transaction Online transaction processing (OLTP) Online analytic processing (OLAP) Analytic db was called a data warehouse
data warehousing
OLTP needs to be highly available and latent so wont let analytics queries run Contains read only copy of OLTP systems ETL extract transform load, periodic or streaming
divergence for data and OLTP
Relational sql for queries but implemented differently. Paraccel, redshift, hive, spark, presto, drill
stars and snowflakes schemes for analytics
Star schema (dimensional modeling) Fact table - each row is an event, purchase, click, page view Foreign keys to other tables called dimension tables like store id or customer id or product sku. Date is even a foreign key so you can encode holidays and weekday.
Called star because fact table is in the middle surrounded by its dimension tables. Star Schema
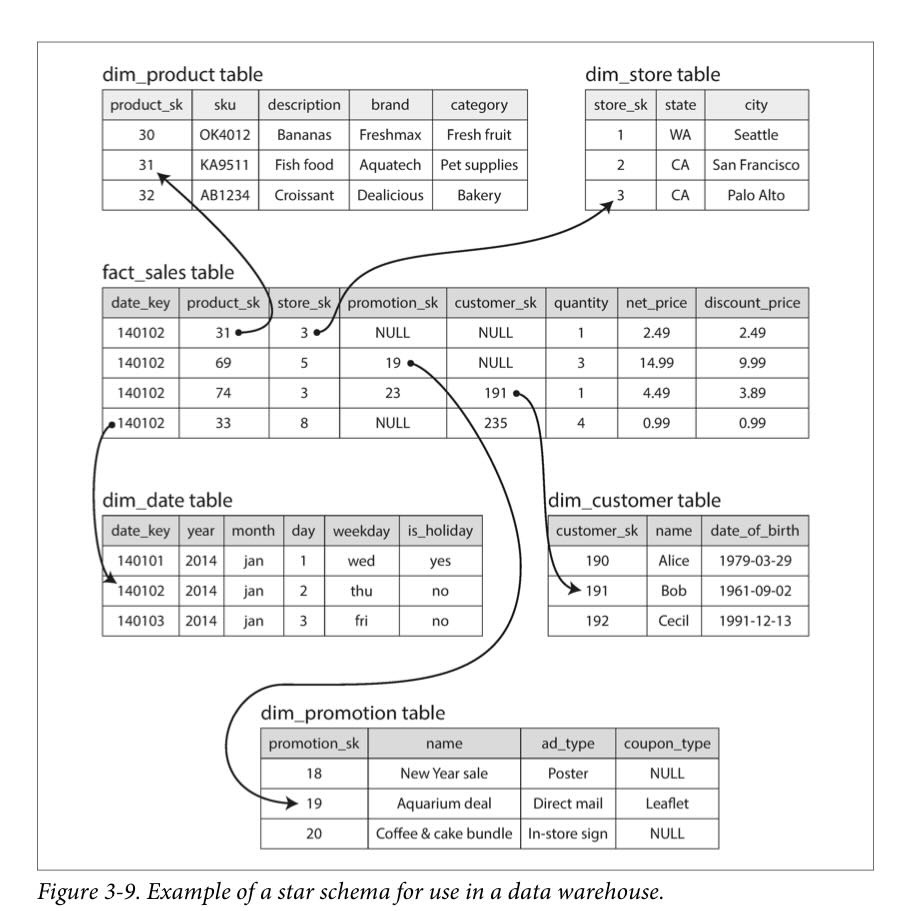{kind=link}
A variation is called snowflake schema - dimension tables are broken down into sub dimensions. Could have brand and category foreign keys. Snowflake are more normalized than star schemas but star schemas are often preferred because they are simpler for analysts to work with.
Data warehouses tables are very wide. 100s of columns in the fact table and the dimension table
Column-Oriented Storage
Trillions of rows and petabytes of data in fact tables storing them efficiently becomes a problem. Even though they are 100 columns wide, a warehouse query might only access 4 or 5 of them.
OLTP storage is laid out in a row-oriented fashion. You can have indexes on different columns but you still need to load all of those rows into memory and parse them. Column oriented stores the values from each column together instead. Each column is in a different file
Can take the 23rd entry from each column file
Column compression
Bitmap encoding & run length encoding May have billions of rows but only 100k products. Columnar structure allows for more rows from a column to fit int the same amount of L1 cache and using bitwise AND and OR allows for vectorized processing
Sort order in column storage
Order doesn’t matter. Easier to sort in insertion order so inserting means appending. Can’t sort column independently since we rely on kth row in each column file
Can choose first, second columns to sort on Helps with queries and compression
several different sort orders
Vertica stores the same data in several different ways/sort indexes. We already have replicas, Query engine will choose which replica to run the queries on
Writing to column-oriented storage
Makes writes slower. Update in place like b-trees would require rewriting all the column files the insertion has to update all the all columns consistently
LSM-tree. In-memory store -> sorted structure prepared for disk. Merged with column files on disk and written to new files in bulk
Aggregation: data cubes and materialized views
Cache some of the counts or sums that queries use materialized view copy of the query results, written to disk. Data cube is computed on writes which works well for analytics db
Summary
OLTP and OLAP - OLTP is user facing. Huge volume of requests. Small number of records touched in each query. - Data warehouses each query is very demanding B-tree and LSM tree. Appending vs in place. LSM have higher write throughput
Chapter 4 Encoding and Evolution
Old and new versions of code and data formats. Backwards and forwards compatibility. Forward compatibility is trickier. Formats for encoding data, JSON, XML, Protobuf, Thrift and AVRo.
Formats for Encoding Data
1. In memory kept in objects, structures, lists, arrays, hash tables, trees and so on. Optimized for efficient access and manipulation by the cpu
2. Write to disk or over the network some kind of self-contained sequence of bytes
We need a translation between the two representations. Marshaling and unmarshaling
Language specific formats
Java has io.serializable, ruby has marshal, python has pickle. They allow in memory objects to be saved and stored with minimal additional code. Problems: - Reading the data in another language is very difficult. Preventing you from using other tech for a long time - Decoding needs to instantiate arbitrary classes. Attackers can get you to run arbitrary code - Versioning is often an after thought - Efficiently is often an after though
JSON, XML, and Binary Variants
Problems: - Ambiguity around encoding of numbers. XML and CSV number and string that has digits look the same, json floats and ints can’t specify precision - JSON and XML support Unicode but not binary strings. Use base64 encoded instead but increases size by 33% - CSV doesn’t not have any schema These remain popular especially for interchange formats. Sending data from one org to another.
Binary encoding
For data used within the org you want to use less space for terabytes. Message pack goes from 81 bytes to 66 vs 32 for next section
Thrift and Protocol Buffers
Apache thrift, google pb both open source Both require a schema in an IDL interface definition language They save because they don’t have to pack in the definition/keys into the packing
Field tags and schema evolution
Schema changes over time called schema evolution. Can change optional to repeated in pb
Apache avro 2009 subproject of Hadoop avro idl for human editing and one for machine-readable
Avro library looks up the reader and writes schema side by side and translates
Schema evolution rules
Forwards and backwards because of the schema translation. May only add or remove a field that has a default value.
Encode writer schema in a large file with lots of records at the beginning of the file. Db with written records include a version number AVRO rpc sends the schema version on the connection setup
Dynamically generated schemas
Avro doesn’t contain tag numbers. You can generate an avro schema in the json representation from the relational schema and encode the db using that schema dumping it to an avro object contain file. Each column becomes a field in that record
This way every export you run it auto updates vs having to write it by hand for thrift or pb
code generation and dynamically typed languages
For static typed, these libraries all offer schema generation to type check against. For dynamically typed, they frown against this extra step. You can use avro with or without even in typed by looking at it’s self-describing data.
The merits of schemas
- Pb, thrift and avro are simpler to implement and use so they have more supported languages.
- More compact
- Valuable form of documentation
- Check forward and backward compatibility of changes
- Type checking at compile time
Modes of Dataflow
How data flows between processes: 1. Via databases 2. Via service calls 3. Via asynchronous message passing
Dataflow Through Databases
Process that writes to db encodes, process that reads decodes
Often forward and backwards compatibility is required Need to ensure older code supports preservation of new/unsupported field
Different values written at different times
Data outlives code in dbs. 5 years old data but brand new code. Dbs allow adding a null default value without rewriting.
Archival Storage
Snapshot for data warehouse. Encode the copy of the data consistently with new schema with avro object container files since they are immutable or use Parquet.
Data Flow through services: rest and rpc
Processes that need to communicate over a network. Client and server is most common
web services
When http is used as the underlying protocol its called a web service REST - a design philosophy that builds upon http. Simple data formats, use urls for resources and http features for cache control, authentication and content type negotiation. SOAP - xml-based protocol aims to be independent of html. Comes with a complex multitude of standards. API is described using WSDL with code generation. Not designed to be human readable output and reliant on tools.
problems with RPCs
Try to make a remote call look like a local call. It’s fundamentally flawed because remote is very different from local. - Local call is predictable, succeeds or fails based on your params, remote may need retry - Remote can end with timeout and you don’t know the result - If you retry could be that the response got through and if it’s not idempotent the action could happen multiple times - Execution time is much more variable, congestion or remote service crowded - Can pass pointers to a local, need to encode for remote
Current directions for rpc
New generation of rpc is more explicit about the fact that it is remote. Futures, promises, streams RESTFUL api is good for experimentation and debugging as you can use a web browser or curl. Vast ecosystem of tools
data encoding and evolution for rpc
Can assume servers updated first and clients second. Only need backwards compat on requests and forward on responses. There’s no agreement on api versioning. You may have to support something a long time
Message-Passing Dataflow
Asynchronous message-passing systems Similar to rpc deliver a message to another process with low latency. Similar to db not via network but by an intermediary called a message broker
Advantages compared to rpc: - Can act as a buffer if recipient is unavailable or overloaded - Can automatically redeliver messages to a process that has crashed - Avoids the sender needed to know the ip address of port of recipient. Useful for cloud - Allows one message to be sent to several recipients - Logically decouples sender from recipient, sender publishes and doesn’t care who consumes
message brokers
Open source dominate like Kafka, rabbitmq Sends a message to a topic or queue Message is just a sequence of bytes with some metadata
distributed actor frameworks
Actor model for concurrency in a single process Location transparency works better in actor model because we already assume messages maybe lost. - Akka uses java’s built in serialization by default - Orleans uses a custom data encoding format that does not support rolling upgrade deployments. Custom serialization plugins - Erlang top rolling upgrades need t one planned carefully
Summary
Turning data structures into bytes on the network or on disk Encoding formats and their compatibility Modes of data flow: db, rpc/rest and asynchronous message passing
Part 2 Distributed Data
What happens if multiple machines are involved in data storage and retrieval Why you want to distribute: - Scalability handle more load - Fault tolerant serve even if a machine or data center goes down - Latency for users around the world
Scaling to higher load
Shared-memory architecture. Many disks, cpus and rams can be joined together in one os. A machine with twice as much cpu and ram typically costs more than twice as much.
Shared-Nothing Architectures
Each machine or vm is a node. Each machine uses its cpus, rams and disks independently. Coordination done on software level.
No special hardware required Shared-nothing requires the most caution. Have the most trade offs and constraints.
Replication vs Partitioning
Replication - keep the same copy on several nodes. Redundancy. Can also help performance Partitioning - splitting a db into smaller subsets.
Can often go hand in hand. Partitions and replicas
Chapter 5 Replication
- Keep data geographically close (reduce latency)
- Keep system to continue working if parts have failed
- Scale out that number of machines that can serve read queries
In this chapter assume you can hold a copy of the entire dataset on one machine
Handling changes to replicated data. Single-leader, multi-leader and leaderless
Leaders and Followers
1. One of the replicas is designated as the leader. Clients send their write requests to the leader which writes it to local storage
2. Other replicas are known as followers. Leader sends data change to followers as part of a replication log or change stream.
3. Client can read from the leader or any of the followers.
4. This mode is used in postgresql, MySQL, oracle data guard, mongola and espresso.
Synchronous Versus asynchronous replication
Replication is quite fast less than second but no guarantee. Synch means if the leader fails replica is the same. Disadvantage is if something fails with the replica the write cannot proceed.
Impractical for all followers to be synchronous. If the sync fails one of the others becomes synchronous. Semi-synchronous
Most are fully-asynchronous so some writes are loss. Called weakening durability.
Setting up new followers
Ensure new followers has accurate copy of leaders data 1. Take a consistent snapshot of leaders db at some point. If possible without taking a lock. 2. Copy the snapshot to the new follower node 3. Follower requests all data from snapshot so references position in replication log. Log sequence number 4. When follower has processed the backlog we say it has caught up
Handling node outages
Nodes can go down unexpectedly or due to maintenance. How to achieve high availability with leader-based replication
Follower Failure: catch up recovery
Follower knows the last transaction processed and can request all changes
Leader failure: failover
Clients have to send writes to new leader, replicas consume from new leader 1. Determining leader has failed. Use a timeout or you took it down 2. Choosing a new leader. Election process but best candidates is most up to date 3. Reconfiguring to use new leader. If old leader comes back needs to know it is now a follower
Things that can go wrong: - New leader may not have all the writes if async. What should happen with those missing writes if old leader comes back. The most common solution is to discard - Inconsistency with other storage if you discard old writes - Two nodes could believe they are leader. Called split brain. End up with inconsistencies - Right amount of time to declare leader dead. Temporary load spike vs longer recovery time. A failover in high load could make things worse
Implementation of Replication Logs
Statement-based replication
Leader logs every write request (statement) and sends to its followers. Every insert, update or delete
Can break down: - If a statement uses NOW() or RAND() will get a different value on each replica - If they use auto-incrementing columns, or depend on existing data, they must be executed in the same order. Limiting when there are multiple executing transactions - Statements that have side effects (triggers, user defined functions) may be diff on replicas. Leader can replace non-deterministic with fixed return values. So many edge cases other methods are preferred.
Write-ahead log (WAL) shipping
- Log is append only sequences of bytes contains all writes
- Leader sends it across the network to its followers
- Followers process this log and build the exact copy as the leader
- Main disadvantage is log describes data on a very low level and different versions may not match. If follower can have newer version you can have zero downtime upgrade, otherwise you’ll have downtime
Logical (Row-based) log replication
Different log formats for replication and for storage. Allow replication log to be decoupled from storage engine. Replication log called the logical log.
Writes at gran of row - New values of all columns - For a deleted row, enough info to uniquely identify the row that was deleted. Typically primary key but if no key need all values - If updated, enough to id and the new values of all columns A transaction that updates several rows generates several log records followed by a record showing transaction commit.
More easily kept backwards compat and can be consumed by data warehouses
Trigger-based replication
If you want to replicate a subset of data or from one kind of db to another or if you need conflict resolution logic then you may need to move replication to app layer. Oracle GoldenGate make data changes available by reading the db log. Can instead use triggers and stored procedures
Trigger can run when data changes. Has greater over head and mor e bugs and limitations
Problems with Replication Lag
Many reads read-scaling architecture. Replication lag and query problems can cause problems for applications
Reading Your Own Writes
User submit data and then view. Record in customer db or comment on a discussion thread. Read-after-write consistency Makes no assurances about other writes. - When reading something the user may have modified read from leader otherwise follower. For a users profile only they can change so can read from leader - If most things are potentially editable. Track time of last update and for one minute after last update make all reads from leader. Prevent queries on follower more than one minute behind leader - Client can remember ts of most recent write, can ensure replicas have at least that ts. Can switch replicas or wait until it’s up to date. Could be logical ts like log sequence number - If region distributed, there is additional complexity
Monotonic Reads
See things moving back in time if reads from diff replicas. Lesser guarantee with stronger consistency. Each user always reads from same replica. Hash of user id.
Consistent Prefix Reads
Causal dependencies. Writes related to each other written to same partition
Solutions for Replication Lag
If app would be affected by large replication lag you have to control for it. Chapters 7, 9 and part 3
Multi-Leader Replication
More than one node accepts writes. Forward change Teo all nodes.
Use Cases for Multi-Leader Replication
Barely makes sense in a single data center
Multi-data center operation
Replicas in several different data centers. Tolerate failure or be closer to your users. Could have a leader in each data center.
- Performance: single leader every write must go to the data center with the leader and defeat the purpose of having multiple data centers in the first place. Every write can be handled in a dc and the perceived performance may be better
- Tolerance of data center outages: if dc with leader fails, failover happens, in multi leader, each dc can run while failed comes back online
- Tolerance of network problems: traffic between dc goes over public internet which is less reliable then in dc.
Some dbs support configs and some have external tools. Tungsten replicator for MySQL. BDR for postgresql
Big problem is conflict resolution.
Clients with offline operation
Calendar apps on mobile phone. If you make changes while offline they need to be synced with server and other devices when on line.
Handling Write Conflicts
Biggest problem with multi-leader is write conflicts
Wiki page edited by 2 users
Synchronous versus asynchronous conflict detection
Both writes are successful and detected sometime later in time. To have synchronous detection you’d have to wait for all replicas which defeats multi leader
Conflict avoidance
Simplest way is to avoid. Writes for a particular record go through the same leader. This can fail when a dc or leader fails.
Converging toward a consistent state
Multi-leader no defined ordering of writes so not clear what the final order should be. Convergent resolution: - Give each write an id and pick the write with the highest id. Prone to data loss - Each replica has an id and replica with highest id wins. Also data loss - Somehow merge values merged title (B/C) - Record conflict in an explicit data structure and have app code resolve it later
Custom conflict resolution logic
On write: runs on background processes and must execute quickly. As soon as db detects conflict On read: when conflict is detected all conflicting writes are stored. The application gets all of them and has to resolve the conflict
Theres research into automatic conflict resolution Operational transformation. Concurrent editing of an ordered list of items like in google docs
Booking rooms at same time. Two different leaders might both allow booking. Conflict is bad here
Multi-Leader Replication Topologies
Communication paths along which writes are propagated. Circular, star and all to all. Most common is all to all. Circular and star have trouble with one node failing Ensure your db has the guarantees you think it has so you can check for casuality
Leaderless Replication
Dynamo & Cassandra. Client sends its writes to several replicas vs coordinator does it for client.
writing to db when a node is down
No failover. Reads are sent to several nodes in parallel. Version numbers use for which is newer
Read repair - client sees one replica is out of date when reading
Anti-entropy process - background process look for differences
quorums for reading and writing
If there are n replicas, every write must be confirmed by w nodes and must query at least r nodes. W +r > n
limitations of quorum consistency
W writes may end up on diff nodes than the reads if sloppy quorum. Write happens concurrently with read, write may be reflected only on some replicas If a write succeeded on some but not all and less than w it is not successful and is not rolled back where it succeeded
monitoring staleness
Monitor if db is returning up to date results Metrics for replication lag on leader based.
Leaderless replication has no standard metrics for this.
Sloppy quorums and hinted handoff
Proper quorum doesn’t have failover and doesn’t get slowed down by one node. If there is a network interruption and the client can reach some but not a quorum amount of nodes is it better to fail?
Sloppy quorum - writes and reads still require w and r successful responses but not among the home nodes. Hinted handoff when the home nodes come back online
Multi-data center operations
Leaderless is suitable for multi-data center operation since it can handle conflicting concurrent writes, network and latency
Client waits for quorum of nodes within its local data center
Detecting Concurrent Writes
Events may arrive in different order at different nodes due to delays and partial failures. App developer often has to be aware of this. Most dbs do not handle this well
last write wins (discarding concurrent writes)
Only store most recent and allow older to be overwritten. But we don’t know with concurrent writes. We can force an arbitrary order with time stamps. Called last writer wins LWW Only safe way is a key is only written to once and then treated immutable, Cassandra might use uuid as a key
happens-before relationship and concurrency
- Insert happens before increment. B’s operation builds on A so they are not concurrent. B is casually dependent on A
- When the operation starts each client does not know about the other operation.
A happened before B, b before a or concurrent.
It seems that leaderless are much better except for conflict handling but the author things in the future we’ll discover techniques to fix it. For now the app developer has to handle these cases.
capturing the happens-before relationship
Server can tell whether two operations are concurrent via version numbers A client must read a key before writing Requires the client to do extra work merging and reading Also need to add tombstones so you can signal a delete
Leaderless need version vectors
Chapter 5 Summary
Covered replication. High availability, disconnected operation, latency, scalability Single-leader replication Multi-leader, leaderless
Chapter 6 Partitioning
Partition or shard in mongodb, called a region in Hbase, tablet in big table, a vnode in Cassandra and Riak
Normally each piece of data belongs to exactly one partition. Partition for scalability so you can improve query load.
Skew makes partitioning much less effective. Partitioning and replication are often used together.
Partitioning by hash of key
A good hash function takes skewed data and makes it uniformly distributed
Don’t say consistent hashing. Call it hash partitioning
By using hash we lose efficient range query since keys are no longer adjacent. Can use compound primary key where only part of the key is used to determine partition, the rest of the columns are concatenated into an index (User_id, update_timestap) can efficiently retrieve all updates made by a particular user
Skewed Workloads and relieving hot spots
Consider a celebrities profile where one key is way hotter. Often app will make multiples of that key and combine the reads and writes
Partitioning and Secondary Indexes
Secondary indexes don’t map neatly to partitions: document-based partitioning and term-based partitioning
Partitioning Secondary Indexes by Document
Each car/doc listing has a unique id. You want to let them filter by color, make etc. Each partition maintains it’s own secondary indexes. Doc index is known as a local index since it doesn’t care about others. This means you have to read every partition
Known as scatter/gather Mongodb, riak, Cassandra, elasticsearch, all use document-partitioned Most db vendors recommend you setup your partitioning scheme so secondary index queries can be served from a single partition but might not always be possible
Partitioning Secondary Indexes by Term
Global index that covers data in all partitions which is also partitioned differently than primary key index. Downside is that writes are slower and more complicated. Every term in the document might be on a different partition. Updates to secondary indexes are often asynchronous
Rebalancing Partitions
Things change: - Query throughput increases so you want to add more cpu - Data set size increases so you want to add more disks and ram - Machine fails and other machines need to take over
Strategies for rebalancing
Don’t do hash Mod N because if number of nodes change you have to rebalance everything
Fixed number of partitions
Many more partitions than nodes and assign several partitions to each node.
If you add a new node, they can steal partitions from others
You could assign more to those that are more powerful. Riak, elasticsearch, couchbase and voldemort
Too many partitions too much overhead, too few and they are very large and rebalancing/failover is expensive
Dynamic Partitioning
Key range partitioning with fixed number could end up with all the data in one partition. Hbase and rethink create partitions dynamically. When a partition reaches a certain size (Hbase uses 10GB) split into two partitions. Same with shrinking
Often can do pre-splitting across nodes so that more than one node does work
Partitioning Proportionally to Nodes
Dynamic partition: Number of partitions is proportional to size of the data set Fixed: size of each partition is proportional to the size of the dataset. For both, the number of partitions independent of the number of nodes
Cassandra and Ketama, number of partitions proportional to the number of nodes. Fixed number of partitions per node
Operations: Automatic or manual rebalancing
Gradient of automatic. Couchbase, riak and Voldemort generate a suggested partition assignment but require an admin to commit before it takes effect.
Dangerous to fully auto for the case of a slow node and rebalancing will make things worse, not better.
Request Routing
Someone has to stay on top of those changes. If I want to read or write the key ‘foo’, which IP address and port number do I need to connect to?
Instance of service discovery problem
Approaches: 1. Allow clients to contact any node via round-robin LB, if the node owns the partition can handle it, otherwise it forwards the request to the appropriate node 2. Send all requests to a routing tier which forwards. Does not handle any requests. 3. Require clients be aware of partitioning and connect to the node directly (insane my note)
Many use a separate coordination service such as Zoo-Keeper. Each node registers in zoo keeper and maintains the mapping. Other actors like routing tier or partitioning aware client can subscribe to this info.
Espresso uses Helix for cluster management which uses ZooKeeper.
Cassandra and Riak use a gossip protocol among the nodes. Requests can be made to any and forward (approach 1). More complexity on db node
Couchbase does not rebalance automatically. Configured with a routing tier called moxi which learns from the cluster nodes
Parallel query execution
Massively parallel processing (MPP) big ass joins and filtering covered in chapter 10.
Chapter 6 Summary
Goal of partitioning is to spread the data and query load evenly across multiple machines, avoiding hot spots
Chapter 7 Transactions
Many things can go wrong - Db software or hardware may fail at any time - App may crash at any time - Network interruptions - Several clients writing at the same time - Client may read data that’s only partially updated - Race conditions
Transaction is a tool of choice. Group several reads and writes into a logical unit.
Created to simplify the programming model for applications accessing a db.
Slippery concept of a transaction
Most transactions follow the initial sql database IBM System R NoSQL dropped transactions as enemy of scalability but truth is somewhere in the middle
Meaning of ACID
Atomicity, Consistency, Isolation, and Durability
One db’s implementation of ACID does not equal another’s.
If a system does not meet acid, they are sometimes called BASE (basically available soft state and eventual consistency) which means “not acid” and can mean anything
Atomicity
Cannot be broken down into smaller parts. Another thread cannot see half-finished result of operation for multi-threaded. For ACID it does not mean concurrency. What happens if several processes access data at the same time is covered under isolation.
What happens if a client wants to make several writes but a fault occurs after some writes have been processed.
Aborted transactions rollback
Consistency
Terribly overloaded For acid, certain statements/invariants that must always be true. Application determines consistency invariants like balancing credits and debits. It doesn’t really belong in acid.
Isolation
Concurrently executing transactions are isolated from each other. Textbooks call this serializability. Each transaction can pretend it’s the only one running. ** DB ensures when the transactions have committed, the result is the same as if they had run serially** In practice rarely used because it causes a perf penalty. Often settle for ‘snapshot isolation’
Durability
once a transaction has completed successfully, any data it has written will not be forgotten No real way to 100% prevent loss just risk-reduction techniques, replication, disks, tapes, backups
Single-Object and Multi-Object Operations
Multi object transactions require some way of determining which read and write transactions belong to the same transaction. Typically done on client’s TCP Connection
Non-relational/storage engines universally aim to provide isolation and Atomicity on the level of a single objet on one node. Log for crash recovery and a lock on each object (only one thread to access an object)
Some offer increment and compare-and-set operations which allows the write to happen only if the value has not been changed by someone else
The need for multi-object transactions
Many distributed data stores have abandoned multi-object transactions because they are difficult to implement across partitions, high availability and performance
Do we need them though? - Relational dbs often have foreign key to a row in another table. Multi object transactions allow you to ensure the references are valid - For doc db when updating denormalized info often need to update several documents in one go - Dbs with secondary indexes, the indexes also need to b updated
Handling errors and aborts
Transaction can be aborted and safely retried Rather abandon transaction then leave it half finished
Leaderless replication works on a more ‘best effort’ basis. Leaves app to recover from errors.
Retrying can fail: - Could have succeeded but network failed - Error is due to overload so retry makes it worse - Only worth trying after a transient error - Transaction has side effects outside of the db like sending an email - If the client process fails
weak isolation levels
Concurrency bugs are hard to find by testing, difficult to reason about and difficult to reproduce.
Protect against some but not all concurrency issues. Decide what level is appropriate for your organization
Read committed
1. When reading from db, you will only see data that has been committed
2. When writing, you will only overwrite data that has been committed
No dirty writes
First write starts, second comes in, but first is part of a transaction. Must delay second until first finishes otherwise you are overwriting a dirty write.
Implementing read committed
Default in Postgres, sql, memsql
Prevent dirty writes with row-level locks Prevent dirty reads by db holding old committed value and new value set by transaction holding the lock
Snapshot Isolation and repeatable read
Read skew/no repeatable read is allowed under read committed. Backups and analytic queries cannot handle the temporary inconsistencies. When you copy over the db you need the correct data now.
Each transaction reads from a consistent snapshot of the database. Each transaction sees all the data that was committed in the db at the start of the transaction even if changed by another.
It’s a boon for long-running, read-only queries. Supported by postgresql, MySQL, oracle, sql and others
Implementing snapshot isolation
Readers never block writes and writers never block reads. Multi-version concurrency control (MVCC) keeping multiple versions for one row Implemented with strictly increasing transaction ids
Visibility rules for observing a consistent snapshot
1. At the start of each transaction, db makes a list of all transactions in progress. Any writes those transactions make are ignored
2. Any writes made by aborted transactions are ignored
3. Any writes made by later transactions are ignored
4. All other writes are visible
Indexes and snapshot isolation
Index point to all versions of an object and require an index query to filter out any versions In practice depends on db.
Repeatable read and naming confusion
Can be called serializable or repeatable read. IBM system r’s standard isn’t very clear in their isolation level definition.
Preventing Lost updates
Covered guarantees of read only in the presence of writes.
Read-modify-write cycle, data gets clobbered. Incrementing, changing a json document
Atomic write operations
Implement read-modify-write cycles. UPDATE. Not all writes can be expressed in terms of atomic operations like updates to a wiki.
Explicit locking
App locks objects that are going to be updated (if no built in modify). Consider moving a piece and needing to check if the rules are valid
Automatically detecting lost updates
Could detect a lost update and abort transaction to force a retry. While doing snapshot you can automatically detect when an lost update has occurred
Compare-and-set
If a db doesn’t have transactions often provides compare and set. Only do the update if the content matches what you previously read
Conflict resolution and replication
Preventing lost updates takes more steps since it could be modified concurrently on other nodes Create conflicting versions of a value called siblings and let app code merge after the fact.
Write Skew and phantoms
Consider two doctors checking to call in sick off call. Db says at least 2 so allows concurrent calls and goes to 0. now no doctor is on call
If the two had gone in serial, the second one would not have happened.
Can use a materialized view to create the one on call condition, or explicitly lock the rows the transaction depends on
More examples of write skew
Meeting room booking system - two users try to book and find no one has booked it so both book it. Need serializable isolation Claiming a user name Preventing double-spending
Phantoms causing write skew
Select query for conflicts, decide how to continue, makes a insert, update or delete and commits transaction. Change precondition of second app operation but not its decision
Materialize conflicts
Create a table of time slot and rooms. Create rows for all possible combinations and you can lock the rows Not always possible to do so with a data model and should be a last resort
serializability
Strongest isolation level Handles many problems but hard to implement
Actual serial execution
Remove concurrency entirely, execute one at a time on a single thread. Throughput is limited but works for some ram sized datasets and for analytics workloads
Summary - - Every transaction must be small and fast - Limited to active dataset fits in memory. - Write throughput must be low enough to be handled on a single cpu - Cross-partition transactions are possible but hard limit to extent they can be used
Two-Phase Locking (2PL)
Different from 2 phase commit Writers and readers block writers and readers transactions Locks can have shared or exclusive mode Can have deadlock between transactions and db has to detect and abort one of the transactions
The perf of 2-phasing locking is low throughput and response of queries is long due to overhead of acquiring and releasing locks
Predicate lock for phantom/room booking case
Serializable snapshot isolation (SSI)
First described in 2008 Has full serializability and has only a small performance penalty FoundationDB uses a similar algorithm
Pessimistic versus optimistic concurrency control
Transactions continue in the hope that everything will turn out all right and check when commit if anything bad happened. Only transactions that executed serializably are allowed to commit.
Performs badly if there is high contention or if near max throughput because of increased load from retries
All reads within a transaction are made from the same snapshot
Decisions based on an outdated premise
Transaction is taking action based on a premise (a fact true at the beginning e.g. two doctors on call). DB doesn’t know how the app might use that query result, needs to assume any change in the result means the writes in the transactions would be invalid.
How to detect if the query results changed? 1. Detect reads of a stale MVCC object version (uncommitted write occurred before the read) 2. Detecting writes that affect prior reads (write occurs after the read
Detecting stale MVCC Reads
Track if any ignored writes from the snapshot have been committed, if so abort this transaction. By waiting until the transaction was committed you avoid premature abortion.
Detecting writes that affect prior reads
Transaction modifies data after it has been read When a tx writes to the db must look in indexes for any other txs that have recently read. Similar to acquiring a write lock. The lock as a tripwire.
Whichever txn commits first wins, other aborts
performance of ssi
Rate of aborts is what controls perf.
Chapter 7 Summary
Transactions are an abstraction layer that lets app code pretend some problems don’t exist. Use SSI
Chapter 8 Trouble with distributed systems
Turn our pessimism to the maximum and assume everything that can go wrong will go wrong. Networks, clocks and timing issues
Faults and partial failures
Partial failures are nondeterministic
Cloud computing and supercomputing
- HPC high performance computing. Thousands of CPUs for comp intensive tasks
- Cloud computing, not well defined, data centers, commodity computers, elastic demand, metered billing,
- Enterprise dc lie somewhere in between
Unreliable networks
Shared-nothing computers that can only communicate over the network. Cannot see disk or memory
Lots of ways for asynchronous packet network to fail and return in non-deterministic amount of time.
Network faults in practice
One study in a medium sized dc run by one company, 12 network faults a month, half disconnected an entire rack. Adding redundant networking gear doesn’t reduce faults as much as you might hope since it doesn’t guard against human error.
Detecting Faults
You may get some response or error notification for nodes but sometimes you will not. You must plan for no response at all and plan for a timeout
Timeouts and Unbounded Delays
Hard to choose timeout length Network congestion can often be caused by switch queue filling up
Queueing on vm, os, and tcp
Best is to jitter and automatically adjust timeouts according to observe times. Phi Accrual failure detector used in Akka and Cassandra
Synchronous vs Asynchronous
Packet switching are optimized for bursts traffic vs a circuit which needs a constant number of bits. There are some tech that provides this but probably not relevant.
Unreliable Clocks
Clocks measure duration and points in time. Most computers use their quartz and NTP and servers get time from GPS receivers
Time of day clock - return current time and date. Synch’d with NTP. Monotonic clock - suitable for measuring duration
Quartz clock has 17 seconds of drift if reset every day If a computers clock differs too much app might see time go backwards or forwards
Precision time protocol PTP
Use logical clocks, incrementing counters, for ordering events
How do choose txn’s for snapshot? Can use Spanners trutime api with [earliest, latest] confidence interval to detect overlap.
Process Pauses
Processes can pause at any time for more than 15 seconds for say GC VM can be suspended and resumed when it’s migrated. The rest of the world keeps running and may think the node is dead by the time it resumes.
You could use a real time os (RTOS) for worst case execution times
limiting impact of gc
Treat gc pauses like brief planned outages of a node
Knowledge, Truth, and Lies
Truth is defined by the majority
A node cannot necessarily trust its own judgement of a situation. Algorithms require a quorum, including declaring a node dead
Leader and the the lock
If a node continues acting as a the chosen one even though the majority declared it dead, it could cause problems.
Can use
Fencing tokens
Every time a lock server returns a lock or lease also returns a fencing token, a number that increases every time a lock is granted. Every time a client sends a write request it includes its current fencing token. Service can check to see the high watermark of fence token and reject lower so the resumed false leader cannot fuck you up.
Byzantine Faults
Big problem is nodes try to lie or send arbitrary corrupted data
- In aerospace environments, radiation can change data
- With multiple participating organizations may attempt to cheat or fraud
Checksums, sanity checking of values, multiple NTP servers
System model and reality
Timing assumptions synchronous model, asynch and Partially synchronous model - behaves sync most of the time but it sometimes exceeds the bounds.
Node failures: Crash-stop faults - node never comes back Crash-recovery faults - nodes crash and recovery Byzantine faults - nodes may do anything
Safety and liveness properties helps deal with difficult system problems. Safety problems must always hold but lievness you can make caveats. Liveness - something good eventually happens
mapping System models to the real world
What happens if theres a firmware bug or corrupted data Difference between computer science and software engineering is writing code to handle things you assumed to be possible to be in a recoverable state with exits and log messages
Chapter 8 Summary
Async packet network, clocks and pausing all create hard problems we have to think about.
Partial failures will happen.
Chapter 9 Consistency and Consensus
Simplest way to fail is to shut down and show an error message. If not acceptable, we need a way to tolerate faults.
Reaching consensus in spite of network faults and process failures is tricky
Consistency Guarantees
Most dbs have eventual consistency. If you stopped writing eventually all reads would be the same.
This is hard for app developer because db almost looks like a variable but in practice you might hit hard to repro bugs.
- Strongest consistency models in common use linearizability, pros and cons
- Ordering events in a distributed system
- Atomically commit a distrusted transaction
Linearizability
What if db could give the illusion there is only one replica so every client has the same view
Aka atomic consistency, strong consistency, immediate consistency, or external consistency
Consider people check who has won the World Cup after if just finished. Some clients may read from older server if using single leader
What makes a system linearizable
If any one read has returned the value from a new write, they all must. Atomically flip value
Serializability - an isolation property of transactions, where every transaction may read and write multiple objects (rows, docs, records). It guarantees each transaction behave the same as if they had executed in some serial order
Linearizability - a recency guarantee on reads and writes of a register. Does not prevent problems such as write skew.
SSI is not linearizable by design. It makes reads from a consistent snapshot to avoid lock contention. Does not include writes more recent than the snapshot
Rely on Linearizabilty
When is it useful?
Locking and Leader election
All nodes must agree which node owns the lock so it must be linearizable. Apache zookeeper and etc use consensus algorithms to implement linearizable operations in a fault tolerant way
Apache Curator provides higher level recipes on top of zookeeper
Constraints and uniqueness guarantees
A username or email must uniquely identify one user. Think of it as acquiring a lock on their chosen username. Atomic compare-and-set.
a hard uniqueness constraint requires linearizability
Cross-channel timing dependencies
Image resizer. The file storage service needs to be linearizable because you tell the message queue to tell the imager resizer to change the file but if the file system isn’t ready there’s a race condition
There are two communication channels between the web server and resizer, the message queue and the file storage
Implementing linearizable systems
“Behave as though there is only a single copy of the data, and all operations on it are atomic.”
Single-leader synchronous is linearizable so not a good choice Consensus algorithms are linearizable Multi-leader & leaderless are also not linearizable. Even quorums don’t allow for it because of network delay. Same situation as the score of the World Cup. Last write wins as well because they are not consistent with actual event order during to clock skew
The cost of linearizability
CAP Theorem
- If your application requires linearizability, if some replicas are disconnected due to a network problem, they cannot process requests while they are disconnected. They must wait
- If it does not, then each replica can process requests independently so these are more tolerant to network problems
When a network fault occurs, you must choose between linearizability and total availability
Linearizability and network delays
Few systems are linearizable in practice Even ram on a multi-core CPU. Not guaranteed to read the value written by the first thread.
The reason for dropping linearizability is performance, not fault tolerance We’ve proven that the response time of read and writes is at least proportional to the uncertainty of delays in a linearizability system. So it will have worse performance
Ordering Guarantees
- Main purpose of single-leader replication is to determine the order of writes
- Serializability is about ensuring transactions behave as if they were executed in a certain order.
- Use of time stamps and clocks is an attempt to introduce order into a disorderly world
Ordering and Causality
Ordering helps preserve causality - Causal dependency between q& a - Row must be created before it can be updated - If a & b are concurrent, there is no causal link, we know either knew about each other - SSI preserves causality as nothing else will change the view
If a system obeys the ordering imposed by causality, we say that it is causally consistent
Causal order is not a total order
Linearizability - total order. Every op is atomic. None are concurrent Causality - two events are ordered if they are casually related. Incomparable if concurrent
Linearizability is stronger than casual consistency
Linearizability implies causality In many cases, you may only need causality not linearizability. These dbs have not yet made their way into production but is a promising direction for new systems
Sequence Number Ordering
Causality is impractical. We can get a lot of the benefits with number ordering.
Every operation has a unique sequence number. Single leader can put the ops in the rep log and reps do them in order.
non causal sequence number generators
Multi-leader or leaderless case how to make numbers - Each leader has its own independent set of numbers. Eg. One is even and one is odd. Reserve some bits in the binary representation. - Time stamp from time-of-day clock with high enough resolution - Preallocate blocks of numbers. Node a gets 1 to 1000
None of these are causal
Lamport timestamps
Each node has a unique id and keep a counter of operations it has processed. {counter, nodeId} Each node and client keeps track of max counter it has seen so far and includes that in its request
When a node receive that request, it increases its own counter to that max
Timestamp ordering is not sufficient
Does not work in username case because node has to decide right now if it can and doesn’t know if another node is creating an account with that username
Total order only emerges after you have collected all of the operations
Total Order Broadcast
A protocol for exchanging messages between nodes. Two safety properties always be satisfied Reliable delivery - no messages are lost: if a message is delivered to one node, it is delivered to all Total ordered delivery - messages are delivered to every node in the same order
Algorithm will keep retrying so that it gets through when network is repaired
Using total order broadcast
If every message represents a write and every replica processes the same writes in the same order, replicas will remain consistent with each other, known as state machine replication
Can use the same concept for serializable transactions
Order is fixed at the time the messages are delivered, a node is not allowed to insert a message into an earlier position
Total order broadcast is like creating a log
Implementing linearizable storage using total order broadcast
If you have total order broadcast you can build linearizable on top.. 1. Append a message to the log, tentatively indicating the username you want to claim 2. Read the log, and wait for the message you append to be delivered back to you 3. Check for any messages claiming the username that you want. If you are the first then it’s yours and send another write, otherwise abort.
All nodes will agree on which came first because they are all delivered in the same order Ensures writes but not reads You can do extra ops for reads like sending a message and waiting until it gets back to you
Implementing total order broadcast using linearizable storage
Atomic compare-and-set or atomic increment and get
For every message increment and get the integer and attach the value to the message. Send to all nodes and resend fails
These form a sequence with no gaps so if you send message 4 and get a message with 6, you must wait for 5.
Linearizable compare-and-set and total order broadcast are both equivalent to consensus
Distributed Transactions and Consensus
One of the most important and fundamental problems in computing. Get several nodes to agree on something
Leader election, atomic commit
FLP result shows consensus is impossible because of crashes in asynchronous system which says a system cannot use clock or timeout. If an algo can detect crashed nodes with timeout it becomes solvable.
Atomic Commit and Two-phase commit (2PC)
Atomicity ensures secondary index stays consistent
From single-node to distributed atomic commit
First data then the commit record Harder across multiple where you can have violations, timeouts, crashes.
Transaction commit must be irrevocable. You are not allowed to change your mind and retroactively abort a transaction.
Introduction to two-phase commit
An algo for atomic transaction commit across multiple nodes Used internally in some db’s and made available to applications as XA transactions.
Don’t confuse 2PC and 2PL 2PC provides atomic commit in a distributed db, 2PL provides serializable isolation. Totally different concepts
2PC uses a coordinator. A library within the same app process requesting the transaction. Can be a separate process or service. Narayana, JOTM, BTM, or MSDTC
Coordinator: 1. Sends a prepare message to each node asking if ready to commit 2. If all reply yes, the coordinator sends out a commit request 3. If any participant replies no, coordinator sends an abort
A system of promises
Contains two crucial “points of no return” participant votes yes, and when the coordinator decides. Single-node atomic commit lumps these two events into one
Coordinator failure
If the coordinator fails before the prepare, nodes can abort but if they got it and reported yes they must wait for the coordinator. If the coordinator crashes at this point, the node has to wait and is in doubt or uncertain.
Only way for 2PC to complete is for the coordinator to recover. This is why the coordinator writes its commit or abort decision to a transaction log on disk before sending commit or abort requests
Distributed Transactions in Practice
Provide an important safety guarantee but cause operational problems, kill perf and promise more than they deliver.
Many cloud services do not implement distributed transactions
Database-internal distributed transactions - all dbs running same.software and can use optimizations. Can work quite well Heterogenous dist txns - participants are from two or more diff technologies, dbs from diff venders or even message brokers. Must ensure atomic commit even though diff under the hood which is challenging
Exactly-once message processing
Heterogenous distributed transactions allow powerful integration. A message from a message queue can be ack’d as processed if and only if a db txn for processing was successfully committed.
Atomically committing the message ack and the db write in a single transaction. Will revisit in chapter 11
XA transactions
X/Open XA is a standard for implementing two-phase commit across heterogenous tech. Introduced in 91 and Postgres, MySQL, db2, sql, oracle and message brokers like activemq, hornetQ, misma, and IBM me support
XA is not a network protocol, a C API for interfacing with a transaction coordinator
If your driver supports XA, it calls XA to find out if an op is part of a distributed transaction.
Transaction coordinator implements the API and is a library in the same service as the app.
This means crashing app causes trouble.
Holding locks while in doubt
We care about doubt because db’s take a row-level exclusive lock while waiting for the second commit message. Db can’t release until the transaction commits or aborts.
No other transactions can modify those rows or maybe even read.
Recovering from coordinator failure
In theory if it crashes, should cleanly recover state from the log. In practice orphaned in-doubt transactions do occur. Only way out is for an admin to manually decide whether to commit or rollback the transactions
Many XA implementations have an emergency escape hatch
Limitations of distributed transactions
Transaction coordinator is itself a kind of db If coordinator is part of the app server, its no longer stateless. Distributed transactions amplify failures, since for SSI all participants must respond
Fault-Tolerant Consensus
One or more nodes propose values and the consensus algorithm decides on one of those values.
Must satisfy the following properties:
uniform agreement - no two nodes decide differently integrity - no node decides twice validity - if a node decides value v, then v was proposed by some node termination - every node that does not crash eventually decides some value
Termination says even if some node fails, other nodes must still reach a decision.
Fewer than half the nodes crash
Consensus algorithms and total order broadcast
Viewstamped replication, paxos, raft, and zab for algos
They implement total order broadcast directly because that is more efficient than dong doing repeated rounds of one-value-at-time consensus
Epoch Numbering and Quorums
Epoch number and guarantee that within each epoch, the leader is unique This election is given an incremented epoch number, leader with higher epoch number prevails
For every decision leader wants to make, must send proposed value to the other nodes and wait for a quorum to respond in favor. A node votes in favor if it is not aware of any other leader with a higher epoch.
Two rounds of voting: 1. Choose a leader 2. Vote on a leader’s proposal key insight quorum for two votes must overlap. At least one node in both.
Limitations of consensus
The benefits come at a high cost. The votes are synchronous replication. Need a minimum of 3 nodes to tolerate one failure (remaining 2 of 3 form majority) Dynamic membership extensions to voting are much less well understood.
Consensus systems generally rely on timeouts to detect failed nodes which is tough in geo distributed and cause extra elections
membership and coordination services
Zookeeper and etcd As an app developer unlikely you use it directly, will rely on it indirectly as part of some other project. Offers linearizable atomic operations, total ordering of operations, failure detection, and change notifications
allocating work to nodes
Partition assigning can be done with zookeeper and curator
Data on zookeeper is quite slow-changing “the node running on 10.1.1.23 is the leader for partition 7”
Service discovery
Find out which ip address you need to connect to in order to reach a particular service. When services start register in a service registry
Membership services
Determines which nodes are currently active and live members of a cluster.
Useful for a system to have agreement on which nodes constitute the current membership.
Chapter 9 Summary
Consistency and consensus Linearizability - make replicated data appear like one copy, and make all ops act on it atomically. Too slow for perf
Causal consistency doesn’t have the perf problems and is much less sensitive to network problems.
Considered the username registration case. Lead us towards consensus. Lead us towards broadcast and two-phase commit
Several problems are reducible and equivalent to consensus: Linearizable compare-and-set registers - decide whether to set its value based on whether its current value is equal Atomic transaction commit - db must decide whether to commit or abort a distributed transaction total order broadcast - messaging system must decide on the order in which to deliver messages membership/coordination service uniqueness constraint - decide which transaction gets to create the same key
Zookeeper provides outsourced consensus, failure detection and membership service. Not easy to use but better than rolling your own
Part 3
Derived data Integrating multiple different data systems, potentially with different data models and optimized for different access patterns into one coherent application architecture
Systems of record and derived data
Systems of record - source of truth, when user input comes in, first written here. Each fact is represented exactly once, typically normalized
Derived data system - transforming or processing another system. If you lose derived data you can recreate it again. A cache is a classic example. Denormalized values, indexes and materialized views fall into this category
Chapter 10 Batch Processing
Services - service waits for client request, handle and send response. Response time is primary measure
Batch processing - takes a large amount of input data, runs a job to process it, and produces some output data. Jobs often take a while (from a few minutes to several days). Run periodically. Primary perf is throughput (time to crunch through certain size)
Stream processing systems (near real time systems) - consumes inputs and produces outputs like batch but operates on events shortly after they happen. Lower latency than batch
Batch Processing with Unix Tools
Web server appends a line to a log file every time it serves a request
Could use Unix tools to find the five most popular pages Cat /var/log/nginx/access.log | Awk | Sort | Uniq -c | Sort -r -n | Head -n 5
sorting versus in-memory aggregation
Hash table vs merge sort with disks depends on size of data
The Unix philosophy
Key idea of Unix: we should have some ways of connecting programs like a garden hose — screw in another segment when it becomes necessary to massage data in another way.
1. Make each program do one thing well. To do a new job, build afresh rather than complicate old programs
2. Expect the output of every program to become the input to another. Don’t clutter output with extraneous info.
3. Design and build software to be tried early, ideally within weeks
4. Use tools in preference to unskilled help even if you have to detour to build the tools and expect to throw some of them out after you’ve finished using them
a uniform interface
In Unix, program to program interface is a file. Unix assumes sequences of bytes is ascii text with \n separators
Use of stdin and stout lets users control the input and output. Does’t know or care where the input and output is coming/going
transparency and experimentation
- Input files are immmutable, can run the commands as many times as you want, trying different options
- End the pipeline at any point, pipe into less and look to see the form
- Write output to a file at one stage and start later
Mapreduce and distributed file systems
Lots on mapreduce here Mapreduce reads files on a distributed file system. Hadoop uses hdfs
Common for mapreduce job to be chained together into workflows. No particular support, first job writes to a dir, second job reads from that
Reduce-Side Joins and Grouping
Foreign key in relation model, doc reference or edge in a graph model
For joins in batch processing, we assume a job is processing the data for all users simultaneously
example analysis of user activity events
Log of events describing what a user id did and a user db
Join to figure out whats popular with age groups
Take a copy of the user db (ETL Process) put it in the same distributed file system as the log of user activity. Mapreduce to bring together
Sort-merge joins
Purpose of a mapper is to extract a key and value from each input record
Key would be user id and value activity Another would go over the db extracting the user id and users birthday as the value
Reducer called once for every user id, thanks to the secondary sort (user db record first followed by events in timestamp order). The first value is the date of birth record. Stores the dob I na local var and iterates over the activity events with the same user id outputting {viewed-url, viewer-age-inyears}
The next mapreduce job could then calculate the distribution Known as sort-merge join since mapper output is sorted by key and reducers merge together the sorted list of records from both sides of the join
Bringing related data together in the same place
In a sort-merge join, mappers and sorting make sure all the data to perform the join is in the same place: a single call to the reducer. Reducer is a straightforward piece of code that can churn through records
Mapper emits a key-value pair the key is like an address to destination of reducer. Separated the physical network communication aspect.
Group by
Implement grouping with mapreduce is to setup mappers so the key-value pairs use the desired grouping key.
Handling skew
Bringing all the records with the same key to the same place breaks down with skew. Pig first runs a sampling job to determine which are hot. Send records relating to hot key to one of several reducers. For other input to the join, records relating to the hot key need t one replicated.
Map-Side joins
Join algos in last section perform the joins in the reducer known as reduce-side joins.
Mappers take the role of preparing the input, getting the key and value and assigning it to a reducer partition, sorted by key
Reduce-size approach makes it so you don’t have to make assumptions about the input but the downside is it can be quite expensive. Data may be written to disk several times
No reducers and no sorting. Mapper reads one input file block and writes one output file to the file system.
Broadcast hash joins
Large dataset joined with a small dataset. Small data set can be loaded into memory in each mapper
Small input is ‘broadcast’ to each mapper into a hash table. Simply look up the user id for each event in the table.
This is supported by pig, hive, cascading and crunch and impala
Partitioned hash joins
Partition the user db to the last decimal digit of the user id and then can use broadcast hash. Bucketed map joins
The output of batch workflows
Why run these jobs in the first place?
Building search indexes Build machine learning systems such as classifiers (spam filters, image recognition) and recommendation systems
Some kind of db key/value store. Querie by user id to get suggested friends.
How does web server get this data? Build db in map reduce and when done it can handle read-only queries. Voldemort, terrapin, elephantdb and hbase support this
philosophy of batch process outputs
Hadoop uses more structured file formats like avro and parquet Separate logic from wiring
Comparing Hadoop to distributed databases
Hadoop is somewhat like a distributed version of Unix HDFS is the filesystem and mapreduce is a quirk implementation of a Unix process
Diversity of storage
Hadoop opened up the possibility of indiscriminately dumping data into HDFS and only later figuring out how to process it further
In practice, it appears making data available quickly is often more valuable than trying to decide on the ideal data model up front
Diversity of processing models
Massively parallel procession (MPP) databases are monolithic, tightly integrated pieces of software that take care of storage layout on disk, query planning, scheduling and execution
Not all kinds of processing can be sensibly expressed as SQL queries Machine learning & recommendation systems, full-text search indexes with relevance ranking models, or performing image analysis. You need a more general model of data processing
You can use different workloads on top of Hadoop. Neither hbase nor impala use mapreduce but they use hdfs
designing for frequent faults
Batch processes are less sensitive to faults since it doesn’t immediately affect users and can be run again
MPP will run the entire query again if a node fails since most queries or seconds or minutes this is acceptable
Mapreduce is meant for long running jobs. The og google index map reduce was run on unused prod hardware so had a 5% chance of each job being killed so it was designed for frequent task termination.
YARN, mesos or kubernetes do not support general priority prempetion as cluster schedulers
Beyond MapReduce
Mapreduce is simple to understand but is quite hard and laborious to use. You would have to implement join algorithms from scratch
Pig, Hive, cascading, crunch built on top of map reduce Mapreduce is very robust but other tools are orders of magnitude faster for some kinds of processing
Materialization of Intermediate State
Sometimes mapreduce job output is just intermediate state not read by anyone. 50 or 100 in a row lots of intermediate state. Process of writing out this intermediate state to files is called materialization.
This causes a lot of slow downs and complexity
Dataflow engines
Spark, Tez and Flink. They handle an entire workflow as one job rather than breaking it up into independent sub jobs
Call a user-defined function to process one record at a time on a single thread We call these functions operators and don’t have to be just map and reduce.
Based on research systems like Dryad and nephele Advantages: - Expensive work such as sorting need only be performed in places where it is actually required rather than by default between every map and reduce - No unnecessary map tasks since the work could be done by the preceding reduce operator (mapper does not change the partitioning of a dataset) - Joins and data dependencies are explicitly declared, the scheduler has an overview and can make locality optimizations - Sufficient for intermediate state to be kept in memory or written to disk instead of HDFS - Operators can start once their input is ready, don’t need the entire preceding stage - Existing jvm processes can be reused to run new operators reducing startup overheads
Fault tolerance
Materializing intermediate state makes fault tolerance easy. Spark, flick and tez avoid writing to hdfs so they must track and recreate a lost piece of data. This works if the computation is deterministic. If non-deterministic, kill the downstream operators as well and restart
Iterating over a hash table is no deterministic so use a fixed seed
Graphs and Iterative processing
Data flow engines typically arrange operators in a job as a DAG but the data itself is typically relational-style
In graph processing, the data itself has a form of a graph
Files containing vertices and edges Cannot express ‘repeating until done’ so we use iterative style: 1. External scheduler runs a batch process to calculate one step of the algorithm 2. Scheduler checks whether it has finished (no more edges to follow or the change is below some threshold) 3. Goes back to step 1 and runs another round of the batch process
Pregel Processing Model
Bulk synchronous parallel (BSP). Apache giraph, spark’s graphx, and flink’s belly Known as pregel
One vertex ‘sends a message’ to another sent along edges in a graph. A function is called for each vertex, passing it all the messages sent to it. In pregel, vertex remembers its state in memory from one iteration to the next
Chapter 10 Summary
Batch processing and the Unix design principles. Pipes and files
Chapter 11 Stream Processing
Batch processing had the assumption of bounded input. Daily batch processing means you only have the output a day later Stream refers to data that is incrementally made available over time
transmitting event streams
Record is normally known as an event. Maybe a string, json or some binary form. Could store by appending it to a file, inserting it into a table or writing it to a document db or send it to another node
In batch, a file is written once and read by multiple jobs. In streaming, an event is generated once by a producer (publisher) and processed by multiplier consumers
Related events are grouped together into a topic or stream.
Better to notify consumers rather than have them poll
Messaging systems
1. What happens if the producers send messages faster than the consumers can process them? System can drop messages, buffer in a queue or apply back pressure (blocking producer). If buffers how? Does it write to disk
2. What happens if nodes crash or temp go offline — are any messages lost?
Direct messaging from producers to consumers
- UDP multicast. Used in financial industry for stock market. App level protocols and recover lost packets
- Brokerless messaging libraries such as zeromq and nano msg. Implementing publish/subscribe over tcp or ip
- StatsD and Brubeck use UDP for collecting metrics from all machines
- Producers can make a direct http or rpc request. Idea behind webhooks
They require app code to be aware of message oss and the faults they can tolerate are limited.
Message brokers
A kind of db that is optimized for handling message streams. Can tolerate clients that come and go. Some keep messages in memory while some write them to disk. Normally can grow unbounded
message brokers compared to databases
Some can participate in 2PC using XA or JTA. Still some diff between brokers and dbs: - Dbs keep data until explicitly deleted, brokers delete when it has been successful delivered to consumers. - They assume their working set is small so if it has to buffer more messages everything will be slower - Dbs support secondary indexes, mb’s support someway of subscribing to subset matching some pattern - Mbs do not support arbitrary queries RabbitMQ, activeMQ, hornetQ, Qpid, TIBCO enterprise message service, azure service bus, google cloud pub/sub
Multiple consumers
When multiple consumers read the same topic
Load balancing - each message is delivered to one of the consumers. Useful when expensive to process Fan-out - each message is delivered to all of the consumers. Allows multiple consumers to tune in without affecting each other
You can combine the two patterns. Two groups each subscribe but split up within the two groups
Acknowledgments and redelivery
To ensure a message is not lost, a client must explicitly tel the broker when it has finished processing so the broker can remove it from the queue
MB might resend after a timeout but then you must think about ordering
Partitioned Logs
Batch Job mindset is you can experiment without damaging the input. AMQP/JMS style messaging: receiving a message is destructive if the ack causes it to be deleted so you can’t run the same consumer again and get the same result
Can we have a hybrid? Combining durable storage of db with low latency notif of messaging? log based message brokers
Using logs for message storage
Log is an append-only sequence of records on disk
Producer sends message by appending to end of log, consumer receives messages by reading it sequentially
Achieve higher throughput partitioning the log. A topic can be a group of partitions Within a partition, a broker uses a monotonically increasing sequence number. Kafka, amazon kinesis streams and DistributedLog
Logs compared to traditional messaging
Trivially supports fan-out message b/c they can read the log without interfering Load balancing - broker can assign entire partitions to nodes in the consumer group
Might be preferable to use JMS/AMQP style if message ordering is not important
Consumer offsets
Broker periodically records the consumer offset for clean up and if a consumer dies
Disk space usage
Log is divided into segments and from time to to the old segments are deleted or moved to archive
When consumers cannot keep up with producers
Can raise an alert if a consumer fails significantly behind
Replaying old messages
Client controls it’s offset so it can replay messages and write them elsewhere to experiment/test
Databases and Streams
A replication log is a stream of db write events produced by the leader. Followers apply that stream
Keeping systems in sync
No single system that can satisfy all data storage, querying, and processing needs. OLTP to serve user requests, cache to speed up common, a full-text index to handle search queries, a data warehouse for analytics.
If periodic full db dumps are too slow, an alternative is app code explicitly writes to each system when data changes. Problems with concurrency and performance, one failing and one succeeding
Change Data Capture
Db replication logs have been internal but there has been interest in change data capture (CDC) especially if changes are made available as a stream as they are written
implementing change data capture
Log consumers are derived data systems CDC makes one db the leader and the others into followers. Log based message broker is well suited for transport events from source
LinkedIn’s Databus, Facebook’s Wormhole, Yahoo’s Sherpa use this idea at scale. Bottled water implements CDC for Postgres
CDC is asynchronous
Initial Snapshot
Keeping full log forever would take too much and only recent items wouldn’t include full data so you need a snapshot that must correspond to a known position in the log. Some cdc apis have this functionality, some manual
Log compaction
Log compaction keeps all the keys but updates them. Also looks at tombstones/deletions. New derived data systems start from offset 0 of log-compacted topic. Supported by Apache Kafka
API support for change streams
More dbs support cdc then before. Kafka connect is an effort to integrate CDC tools for a wide range of systems with Kafka
Event Sourcing
- In CDC, app writing to db doesn’t know cdc is happening. Consumers use log of changes
- In event sourcing, app writes immutable events to the event store. Updates or deletes are discouraged or prohibited
Record the user’s actions as immutable events rather than recording the effect of those actions on a mutable db.
Storing “student cancelled their courses enrollment” s “one entry was deleted from enrollments table and one cancellation reason was added”
Deriving current state from the event log
Need to take log of events and transform it into app state suitable for showing to a user (write to read)
Log compaction for events - CDC event contains the entire new version of the record so most recent event for that primary key is kept - Events are modeled at a higher level. Later events do not override prior events and so you need the full history
Intention is that the system is able to store all raw events forever but can do snapshots
Commands and events
Distinguish between evens and commands. When a request comes in, it is initially a command Any validation of a command needs to happen before it becomes an immutable event. Like requesting a seat
State, Streams, and immutability
Dbs store the current state of the app optimized for reads and serving queries. How does this fit in with immutability which is what makes event sourcing and cdc powerful?
No matter how the state changes, there was always a sequence of events that caused those changes. Mutable state and append-only log are two sides of the same coin
Log compaction is a bridge between log and db state. Retains latest version of each record
Advantages of immutable events
Accountants have been using immutability for centuries in bookkeeping. Append-only ledger Add and remove an item from the cart
Deriving several views from the same event log
Can derive several different read-oriented representations from the same log of events. See Druid, pistachio and Kafka connect
Having an explicit translation step from event log to a db makes it easier to evolve your application over time
You can add a new view and run systems side by side instead of migrate
Normalization debates become irrelevant if you can translate data from a write-optimized event log to read-optimized appplication state. Command query responsibility segregation (CQRS)
Concurrency Control
Biggest downside is write to the log and then read from log-derived view that doesn’t have the write reflected yet
Limitations of immutability
Many systems rely on immutability like Git. How reasonable is it to keep copies forever? Depends on churn
You may have to remove events for privacy or legal regulations. Datomic calls this feature excision.
Processing streams
What you can do with streams once you have it
1. Take the events and write it to a db, cache, search index where it can be queried by other clients
2. Push the events to the users in some way, sending email alerts or push notifications or by streaming the events to a real-time dashboard. A human is the ultimate consumer of the stream
3. You can process one or more input streams to produce one or more output streams
In the rest of the book discuss option 3. Known as an operator or a job.
Diff from batch job because a stream never ends. Sort-merge joins cannot be used. Diff fault tolerance since you can’t restart a many years job
Uses of Stream processing
If an org wants to be alerted if certain things happen - Fraud detection systems need to determine if the usage patterns of a credit card have unexpected changed and block the card - Trading systems need to examine price changes in a financial market and execute trades according to specified rules - Manufacturing systems need to monitor the status of machines in a factory and quickly identify the problem if there is a malfunction - Military and intelligence systems need to track the activities of a potential aggressors, and raise the alarm if there are signs of an attack
Complex event processing
CEP. Specify rules to search for certain partners of events in a stream. The use a high level declarative query like SQL or a graphical user interface. It then maintains a state machine that performs the matching. When found it emits a complex event
DB stores data persistently and queries are transient. CEP queries are long term and events are transient
CEP imps Esper, IBM infosphere, apama, tibco streambase, SQLstream, Samza
Stream analytics
Analytics is more oriented towards aggregations and status Al metrics Bloom filters, HyperLogLog for cardinality estimation, Many distributed stream processing frameworks are designed with analytics in mind, apache storm, spark streaming, flink, concord, samza and Kafka streams. Google cloud dataflow and azure stream analytics
Maintaining materialized views
Deriving an alternative view onto some data set so you can query it efficiently. Application state is also a kind of materialized view. Need to maintain the view forever so counter to analytics assumptions. Samza and Kafka streams
Search on streams
Media monitoring services like houses or stories that match filters. Percolator feature of elasticsearch
Conventional search indeed the docs and runs quieres over the index. Searching a stream, queries the storm and the doc run past the queries
Reasoning About Time
“Average over the last five minutes” Streaming processing use the local system clock on the processing machine (processing time) to determine windowing. Works unless there is any processing lag
Event versus processing time
Confusing event time and processing time leads to bad data. Say you restart the stream processor
Knowing when you’re ready
You can never be sure when you have received all the events for a particular window You could timeout and say this is the window but could have straggler events 1. Ignore straggler events, you can track the number of dropped events as a metric and alert if you start dropping a lot 2. Publish a correction, an updated value for the window with stragglers included, may need to retract previous output
Whose clock are you using, anyway
Log 3 ts: - Time at which the event occurred according to device clock - Time was sent to server according to device clock - Time event was received by server, according to the server Can use the diff between 2 and 3 to fix the clock for 1
There are multiple types of timing windows tumbling, hoping, sliding, session
Stream Joins
Because new events can appear at any time makes stream joins more challenging. 3 diff types of joins
Stream-stream joins
want to detect recent trends in searched-for URLS, event for every time someone types a query and every time someone clicks one of the results. Bring together the events having the same session id.
A stream processor needs to maintain state, all events that occurred in the past hour, indexed by session id
Stream-table joins
Set of user activity events and a db of user profiles
Look at one activity event at a time, look up the events user id and add the profile info the activity event.
Table-table joins (materialized view maintenance)
Twitter timeline example. Timeline cache, per user inbox
Fault tolerance
microbatching and checkpointing
Break stream into blocks, treat each block like a batch. Smaller batches incur greater scheduling and coordination overhead, larger batches mean a longer delay before results of stream become visible
Restarting still causes external side effect to happen twice
Atomic commit revisited
All outputs and side effects of processing an event take effect if and only if the processing is successful
Google cloud data flow and voltdb has this, Kafka in progress
Idempotence
Can make re-publishing idempotent with a bit of extra metadata.
Chapter 11 Summary
Event streams, what purpose they serve and how to process them.
AMQP/JMS style message brokers. Messages are deleted once acknowledged. Async form of RPC Log based message broker. Retains messages on disk
Diff kind of stream joins
Events processing lets you make different read views
Chapter 12 The Future of Data systems
This chapter covers how things should be and has the authors personal opinions
Data Integration
Vendors are hesitant to tell you when their software is poorly suited Even if you understand everything, for a complex app, data is often used in several ways. You have to cobble together several pieces of software
Combining Specialized tools by deriving data
What one person considers to be a central requirement may be obscure and pointless for someone else. Zoom out and consider the data flows across an entire organization
Reasoning about dataflows
Where is data written first, and which representations are derived from which sources?
Keep one system in charge of order of writes and then have derived data systems
Derived data versus distributed transactions
Classic approach for keeping systems consistent is distributed transactions vs derived data systems
Biggest difference is Transaction systems provide linearizability (reading your own writes)
XA has poor fault tolerance and performance characteristics
In the absence of improved distributed transaction protocol, log-based derived data is the most promising approaching for integrating different data systems
Limits of total ordering
Small enough systems, totally ordered event log is possible (see single-leader replication which needs this) Limitations start to emerge: - Requires all events to pass through a single leader node that decides on ordering. If the throughput is greater than one machine than the order is ambiguous - Geographically distributed makes undefined ordering between leaders in different dc’s - Micro services have durable state in each service not shared, no defined order for those events - Some apps work offline, clients and servers are likely to see diff orders
Most consensus algorithms are designed for situations in which the throughput of a single node is sufficient to process the entire stream of events. Still research for algos that scale beyond single node.
Ordering events to capture causality
Imagine social network where removes partner and then sends a messages to all friends about the break up. Intention is ex-partner doesn’t see but friendship status and message status might not be in sync.
Join of friend status and messages
- Logical timestamp require recipients to handle events that are delivered out of order and additional metadata
- Event to record the unfriending and later events reference that event id to record the causal dependency
Batch and stream processing
Goal of data integration is making sure the data ends up in the right form in all the right places
Consuming inputs, transforming, joining, filtering, aggregating, training models, evaluating and writing. Batch and stream processes output search indexes, materialized views, recommendations, aggregate metrics and so on
Stream is unbounded but spark implements it as micro batches so line is blurring
maintaining derived state
Batch has a strong functional flavor. Deterministic pure functions Could maintain state synchronously but the Async is what makes the system robust
Reprocessing data for application evolution
Stream processing allows changes to be reflected with low delay Batch processing allows large amounts of data to be reprocessed
Without reprocessing, schema evolution is limited to simple changes
Derived allows a gradual switch between schemas/restricting
Lambda architecture
Batch for historical, stream for recent how do you combine
Run batch for system of record and streaming for fast updates for a derived view
Unifying batch and stream processing
- Ability to replay historical events through same processing engines that handles stream of recent events.
- Exactly-once semantics for stream processors, discarding the partial output of any failed tasks
- Tools for windowing by event time
Unbundling Databases
Unix viewed its purpose as presenting programmers with a logical but fail rely low-level hardware abstraction Relational dbs give app programmers a high-level abstraction that would hide the complexities of data structures on disk, concurrency, crash recovery and so on.
Pipes and files vs sql and transactions
Composing Data Storage Technologies
Db tech: - Secondary indexes - Materialized views - Replication logs - Full-text search indexes
Creating an index
Create index is similar to setting up new follower replica and bootstrapping cdc in a streaming system. Reprocess data set
Meta-database of everything
Dataflow across an org starts looking like one huge db. Stream is like a db subsystem keeping indexes or materialized views up to date
Federated databases: unifying reads - unified query interface to a wide variety of underlying storage engines and processing methods (reminds me of dremio)
Unbundled dbs: unifying writes - federated answers reading, what about sync-int writes across a system ensure that all data changes end up in the right places even in the face of faults
Making unbundling work
Federated requires mapping one data model into another which is manageable.
When crossing different tech Async event log with idempotent writes >> distributed transactions. More robust and practical Much simpler abstraction and feasible to implement across heterogenous systems
1. Async event streams make system more robust to outages or perf degradation of individual components.
2. Unbundling data systems allows diff software components and services to be developed, improved and maintained independently from each other by different teams. Consistency due to durability and ordering of events
What’s missing?
Don’t yet have the unbundled database equivalent of the Unix shell (high-level language for composing storage and processing systems in a simple and declarative way)
MySQL | elasticsearch -> does the create index and auto i ally update the search index
Designing Applications around Dataflow
Unbundling dbs by composing specialized storage and processing systems with app code is known as “database inside-out” approach.
Building apps around dataflow like visicalc but fault tolerant
Application Code as a derivation function
Executing app code within db like triggers is somewhat an afterthought. Model is transformation of training data
Separation of application code and state
Dbs could be deployment environments for arbitrary app code but they fit poorly for package management, version control, upgrades, monitoring, network services
Mesos, YARN, docker and Kuberenetes are specifically designed for this.
DB acts like a shared Variable that can be accessed synchronously over the network providing concurrency and fault tolerance but you have to poll for changes
Dataflow: interplay between state changes and application code
Interplay between state, state changes, and code that processes them. App code responds to state changes in one place by triggering state changes in another
Maintaining derived data is not the same as asynchronous job execution for which messaging systems are designed - Derived data the order of state changes is important. Message brokers don’t care when redelivering messages - Fault tolerance is key, a single missed message causes the derived dataset to go permanently out of sync
Stable message ordering and fault tolerant processing are stringent demands but much less expensive and robust than distributed transactions
Stream Processors and Services
Subscribing to a stream of changes rather than querying the current state when needed brings us closer to a spreadsheet-like model of computation.
Observing Derived State
Last section discussed process for creating derived data sets and keeping them up to date aka the write path.
Why create it in the first place? This is the read path.